Improving Zero-Shot Voice Style Transfer via Disentangled Representation Learning 방법론
- Duke University, Durham, North Carolina, USA 2Microsoft, Redmond, Washington, USA
- ICLR 2021
핵심 메커니즘만 정리
- AutoEncoder 형태로 bottleneck 구조를 사용하여 speaker identity 정보를 줄이고 Content feature를 담아내려한 content Encoder을 구축하기 위함
- Speech Encoder은 반대로 Speaker identity를 추출하는 Encoder
- Mutual information (MI) : A Crucial concepts that measures the dependence between two random variables.
3. Proposed Model
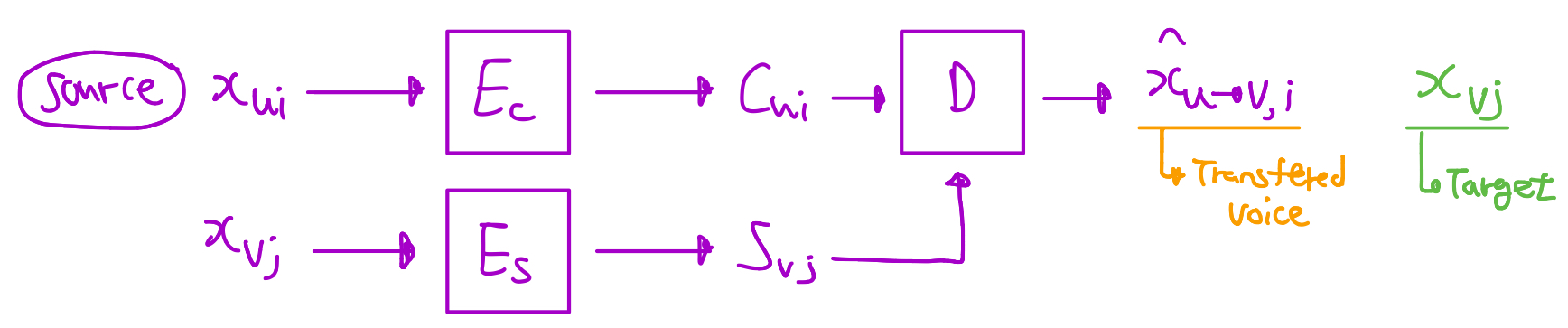
3.1 MI-Base Disentangling Objective
-
Representative 잠재적 embedding인 $(s,c)$을 학습하기 위해서, embedding pair $(s,c)$와 input $x$ 사이의 MI를 최대화하는것이 바람직함
→ Maximize $L(x;s,c)$
→ AutoEncoder로 잘 reconstruction을 하려면 input $x$와 pair $(s,c)$는 MI가 높게하여 즉, distance를 좁게해야함
-
반면에 style embedding $s$ 와 content embedding $c$는 독립적으로 만드는것이 바람직하며 style embedding과 content embedding space를 disentangle하기 위해서 mutual information $L(s; c)$를 최소화함
→ Minimize $L(s;c)$
-
그러므로 전체 Loss는 아래와 같은 식이 나옴 (일단 좌항 부분만 설명함)
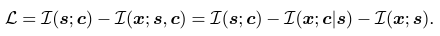
-
Speaker identity $u$값을 ${1,..,M}$형태의 값 변수로 사용함
→ Speaker-related attributes(속성)에 대한 representative 형태의 embedding을 학습시키기 위해서
- Speaker embedding이 나오는 과정은 다음과 같음
- Speaker $u$ 가 있을것이고 그 또는 그녀의 voice로부터 $x_{ui}$가 나올것이고, 이 $x_{ui}$는 Encoder을 통해서 $s_{ui}$가 도출 될것임
- 즉 정리하자면 ( $u$ → $x$ → $s$ ) 순으로 이뤄지고 이런 과정은 Markov Chain이고, 위의 식을 MI data-processing inequality를 기반으로 $L(s;x) \geq L(s;u)$ 를 결론지음
- 그리하여 다음 식이 도출 됨
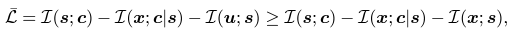
- 이 식에서 이제 좌항만 보면 됨
- 미리 정리하자면 추후 표현될 Loss 값은 다음과 같음
- 전체 Loss
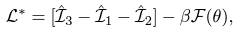
- $\hat{L}_3$ 은 $L(s;c)$ 임
- $\hat{L}_1$ 은 $L(u;s)$ 임
- $\hat{L}_2$ 은 $L(x;c \mid s)$ 임
- $F(\theta)$ : $q_{\theta}(s \mid c)$의 likelihood function으로서 Maximized 됨
- $L(u; s)$의 역할
- 최대화 되어야할 값임
- $u$ speaker의 목소리 $x_{ui}$ 의 style embedding이 $u$의 style centroid와 더 비슷하게 되도록 하기 위해서, MI의 값을 최대화 시키고 반면, $v$의 style embedding과는 연관성이 없게 만들어야 하니까 MI의 값을 최소화 시키도록 하는 것임
- $\hat{L}_1$의 식은 다음과 같으며 이것은 Maximize되는 방향으로 학습에 기여함
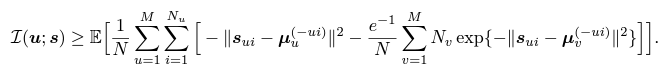
- $L(x;c \mid s)$ 의 역할
- 역시나 최대화 되어야할 값임 (전체 Loss가 작아지는 방향으로 학습되도록 설계)
-
Speaker $u$의 주어진 voice style $s_u$와 content style $c_u$가 잘 어우러져서 original voice인 $x_{ui}$와 거의 비슷해지도록 학습이 되어저야 하니, MI가 커지는 방향으로 진행 될 것임
→ 즉 Distance는 최소화 되는 방향으로 진행
- $\hat{L}_2$의 식은 다음과 같음
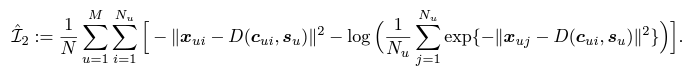
- 이 Loss로 인하여 $x_{ui}$와 $c_{ui}$ 사이의 연관성이 증폭되며, 이는 곧 $c_{ui}$가 content 정보를 보존하는것을 향상시키도록 함
- $L(s;c)$ 의 역할
- 이 MI는 최소화 되어야 할 값임
- 그 이유는 content embedding과 style embedding은 구분 되어야할 성질로 서로 independent하게 하려면 MI값을 최소화 시키는 방향으로 진행되어야 하기 때문
- $\hat{L}_3$ 의 식은 다음과 같음
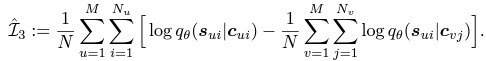
이제 학습하고자 하는 Loss 즉 Objective에 대해서 의미적으로 이해가 되었다.
물론 MI에 대한 구체적 수식을 이해는 온전히 할 필요가 없다.
MI가 연관성을 나타내는 지표로 사용되었다 정도 일단 이해하고 넘어가도 괜찮다.
MI의 구체적 수식도 사용 이유를 볼 때는 중요하지만 논문의 핵심은 그것이 아니다.
Model structure
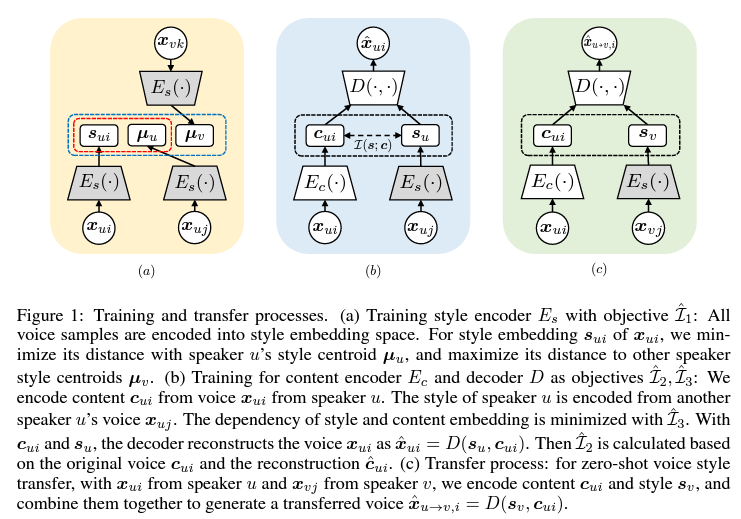
여기서 (a) 모델 구조의 과정을 통해서 $\hat{L}_1$의 값이 도출 되는 것이고, (b) 모델 구조의 과정을 통해서 $\hat{L}_2$, $\hat{L}_3$ 값이 도출 된다.
그리고 위에서 보았듯이 전체 Loss는 이 세 개의 Loss로 구성되어 있다.
즉 이 뜻은 적어도 Training 과정에서 (a), (b)는 동시에 진행된다는 것이다.
그런데 (a)를 보면 style Encoder 형태를 세 개나 사용하고 있고 (a)의 표현을 보면 Training style encoder $E_{s}$라고 나와 있다.
즉 $E_s$를 학습시킨다는 것인데, 이 말 때문에 처음에는 도저히 이해가 안갔다.
$E_s$가 세 개나 있는데 각각을 따로 trainable한 parameter 갱신을 해서 무엇을 어쩌자는건지 이해가 안되었다.
그런데 논문의 후반부에 $E_{s}$는 pretrained GE2E의 weights로 초기화 되었다고 이야기 한다.
GE2E는 speaker의 style을 output하는 모델이라고 생각하면 된다.
즉 pretrained 된 weights를 가져오고 위와 같은 형태로 구성이 되어 Loss를 뽑아 학습과정이 진행되는 것이라면 $E_{s}$의 weights parameter은 untrainable 하도록 하는것이 맞다.
그래야 (a) 구조, 그리고 (b) 구조에 모두 사용된 $E_{s}$에 대해 통일성을 줘야 의미적으로 맞기 때문이다.
그리고 위의 그림을 보면 $E_{s}$가 회색으로 색칠 되어있다.
단순하게 구별하기 위한 용도로 색칠 되어 있을 수도 있지만, 회색이 구별하기 위한 용도라고 하기에는 다른 모듈들은 모두 흰색으로 표현되어 있다.
즉 $E_{s}$는 구조적 학습 및 의미적 상황적으로 보았을 때라도, 그림상으로라도 untrainble한, 즉 frozen된 상태라고 판단해야 맞는것 같다고 나는 생각했다.
(a)의 ‘Training’이라는 첫 단어 때문에 이게 weights들이 trainable한다는것인가 라고 일반적으로 생각했는데 내 생각엔 이 단어를 일단 (a)부분의 forward도 training 과정 중 하나니 넓게 표현한것 같다.
정리하자면 내가 해석한 과정은 다음과 같다.
- (a)와 (b)를 통해서 Loss값이 추출 되므로 이 두개의 모델은 동시에 진행되는것임
- (a) 과정은 backward 과정이 존재하지 않고 전체적 학습에 기여하는 Loss를 제공하는 역할을 하는것임
- 실질적으로 (b) 구조에서의 흰색 부분이 학습되면서 모델이 학습되어 구축되는 것임
(c)는 (a), (b)의 학습 과정 이후 Transfer process인 즉 Test 방법을 이야기 하는것이다.
Encoder Architecture
- 2-layer long short-term memory (LSTM)
- with cell size of 768
- Fully-connected layer with output dimension 256
- The speaker Encoder is initialized with weights from a pretrained GE2E encoder
- Content encoder의 input은 mel-spectrogram신호의 concatenation이고 speaker embedding과 상응함
- Content encoder은 512개 channel을 가진 3개 convolution과
- Cell dimension이 32인 두 개의 BiLSTM으로 구성되어 있음
- AUTOVC를 참조하여 BiLSTM의 forward backward outputs는 16으로 downsampled 시킴
Decoder Architecture
- AUTOVC를 참조하여 initial decoder은 512 channel을 가진 3개의 CNN과 cell dimension이 1024인 세 개의 LSTM과 LSTM의 output을 투영할 또다른 convolutional layer가 80의 dimension을 가지고 있음
- Spectrogram의 Quality를 높이기 위해서 AUTOVC와 마찬가지로, post-network를 사용하였으며 이것은 5개의 convolution으로 구성됨
- 앞의 4개는 512 channels
- 마지막 1개는 80 channels
- Post-network의 output은 residual signal로 볼 수 있음
- 마지막 conversion signal은 initial decoder의 output과 post-network의 output이 직접적으로 더해짐으로써 계산됨
- Reconsturction loss는 initial decoder과 final conversion signal의 output 둘 다 모두에 적용됨
Approximation Network Architecture
- Style과 content embedding의 mutual information을 최소화시키도록 하는 $\hat{L}_3$ 에서
- $q_\theta(s \mid c)$ 가 요구됨
- $q_\theta (s \mid c)$은 Gaussian distribution family임
-
연구원들은 Gaussian distribution family에서 variational distribution은 파라미터화함
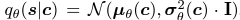
- $\mu_\theta(.)$ : Mean
- $\sigma_\theta(.)$ : Variance
- Two-layer fully-connected networks with tanh(.) as the activation function
- Gaussian parameterization으로 $\hat{L}_3$의 likelihoods는 closed form으로 계산됨
Experiment
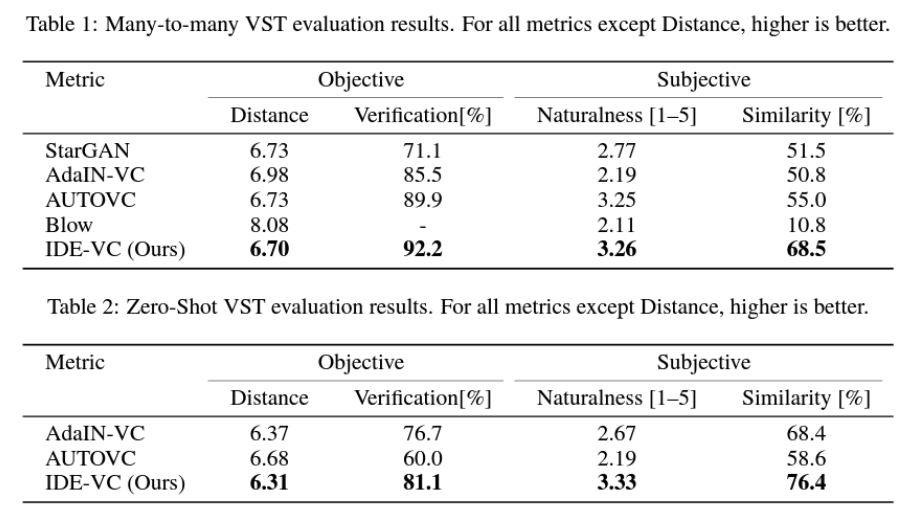
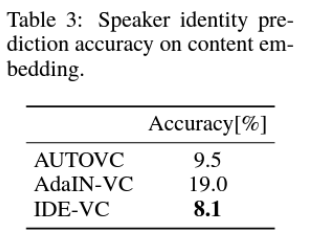
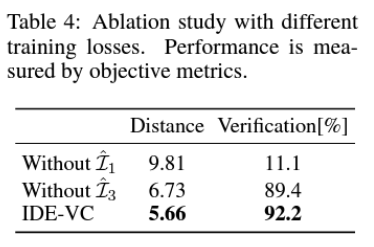
댓글남기기